A common question I get is when it is ok to stop validating a product idea and switch to delivery. It’s a natural question given the pressure product teams face to execute and launch. It’s also an important question. If we stop too early we may end up launching a bad idea (we’ve all been there). If we overdo validation we may waste time and resources with no real benefit.
To answer the question I’ll use the the Confidence Meter, the tool I created to translate evidence into a confidence score.
To make things simpler, I’m going to split the confidence scale into four categories of evidence: Opinions, Assessment, Data, and Tests Results.
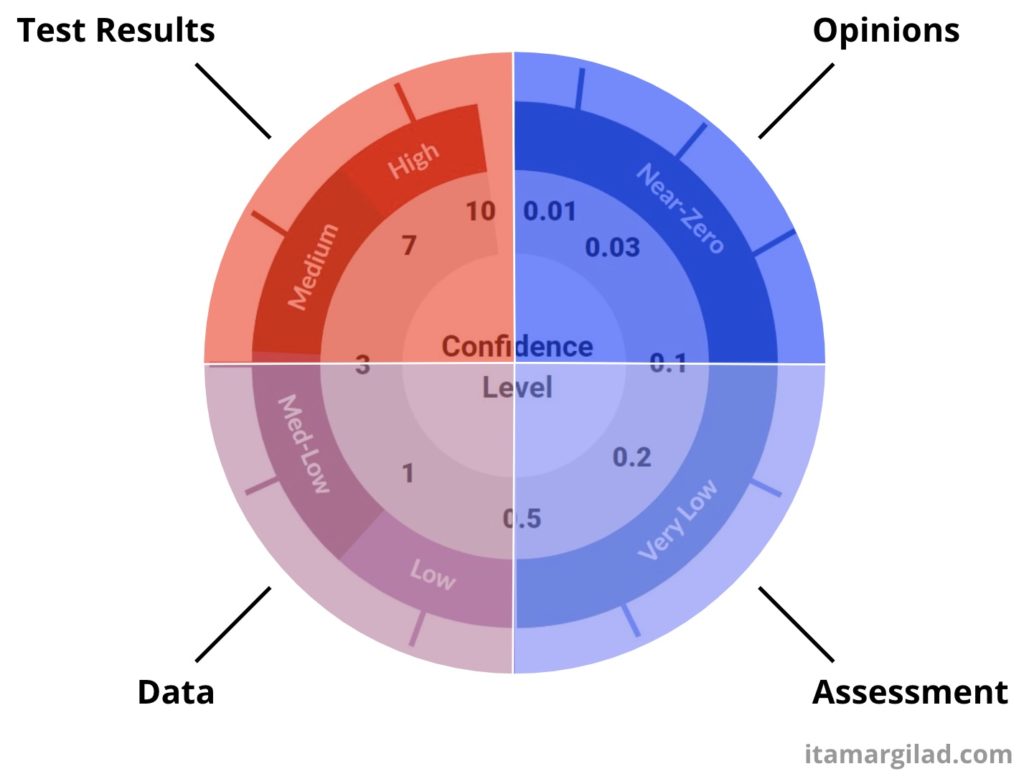
If you’re short for time, here’s the TL;DR:
- Never launch anything solely based on opinions
- It’s ok to release minor tweaks based on assessment
- Having supporting data (without testing) is enough to launch only very small, low-risk, easy-to-revert changes
- Everything else should be validated through tests and experiments. However there are various levels of testing to choose from with different associated costs and confidence levels.
- How much validation you need depends on: a) the cost of building the idea in full b)how risky it is c) your risk tolerance.
Let’s see the details.
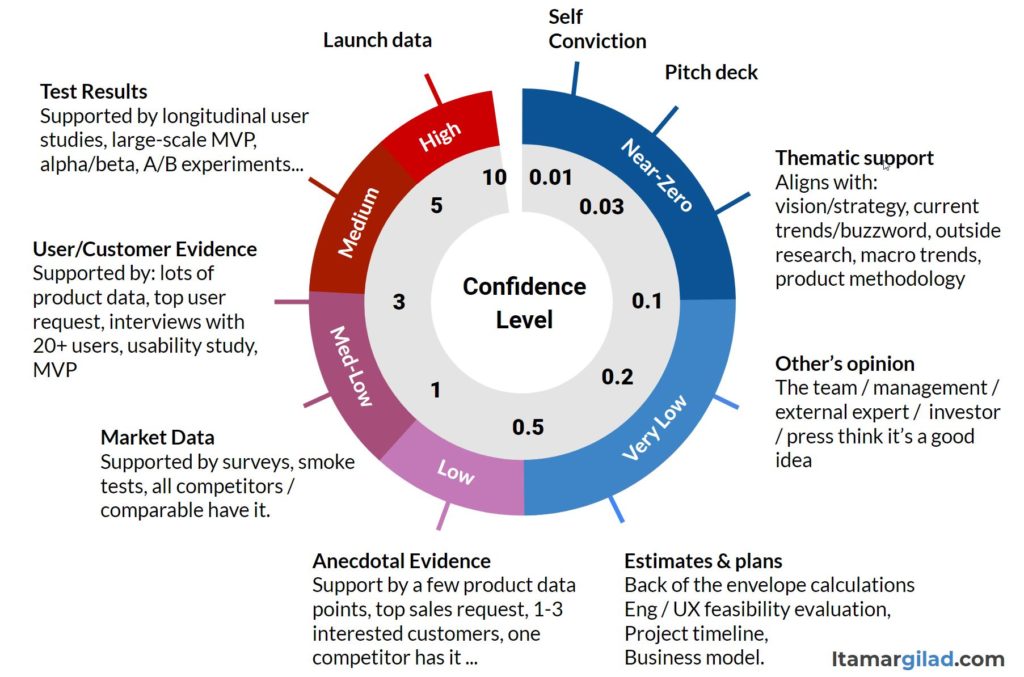
Opinions (Confidence Level <= 0.1 out of 10)
This form of evidence is based on the self conviction of a single person or a small group of like-minded people (who aren’t the intended user). There’s usually some convincing logic behind the idea, and it may be “supported” by some current theme. For example this idea is good because it’s about the Web3, because it strongly aligns with our company strategy, or because Gartner expects the market to grow to $5 trillion in 5 years.
Which ideas should we launch solely based on opinions: None.
While the idea may seem well-substantiated to its originators, it’s really just a matter of their opinions and beliefs. Opinions have been shown time and again to be very weak and unreliable forms of evidence, even when they come from experts or seasoned executives. No one has a crystal ball, and even small changes can cause issues. At the very least we want to venture into the next quadrant of evidence — assessment.
Join 15,000 product people who receive my articles, tools, and templates in their inbox
Assessment (0.1 < Confidence Level ≦ 0.5)
Assessment is about analyzing the idea deeper and with input from more people. Common forms of assessment include:
- ICE analysis – Estimating Impact, Confidence and Ease
- Projections and business models — Using back-of the envelope calculations, business model canvas, and other forms of business/tech analysis to refine our estimates of impact and ease.
- Risk analysis — For example through assumption mapping (for reference consider Cagan’s Four Big Risks)
- Reviews — Including peer reviews, expert reviews, management reviews, and stakeholder reviews. It’s best if these reviews are well structured with a clear agenda and review criteria. Some reviews are best done one-on-one. Importantly, the goal is to get feedback on the idea, not drive decision-by-comittee.
Assessment is still based on opinions and guesses, but we evaluate the idea in a more structured and objective way, and hear more points of view. Often this is enough to surface major flaws in the idea, or to show that it is weaker than other candidate ideas we have. It’s definitely ok to park an idea based on assessment.
Which ideas should we launch solely based on initial assessment?
Assessment without outside data is a very weak form of evidence and can easily send us down the wrong path. The only ideas to consider launching with no further validation, are ones that are:
- Very cheap to implement
- Very low risk
- Create minor/no change to user experience
- Easy to reverse with no permanent damage (eg no service outage or irreversible data loss)
Examples:
- UI tweaks — Color palette changes, changing the order in the settings page, minor redesigns of less-used parts of the UI
- Minor functionality enhancements — A new field in the feedback form, a new user-selected template, new advanced search options.
- Small algorithm changes that theoretically don’t affect user experience
Data (0.5 < Confidence Level ≦ 3)
Assessment helps us understand an idea on a deeper level, but it has limited power without outside data.
Data can come from:
- Customer/user requests
- Customer/user interviews
- Field studies
- Log and usage data
- Competitive research
- Market research
- Surveys
- Other sources
(Sidenote: all the validation techniques I mention in this article are covered in my free eBook: Testing Product Ideas Handbook).
As we gather data we have to differentiate between anecdotal data and market data:
- Anecdotal data (Confidence Level of 1.0 or less) comes from a small set of data points: 1-3 users/customers expressing interest in a feature, a one-of sales request, one competitor has a similar feature implemented.
- Market data (Confidence Level between 1.0 and 3.0) comes from larger datasets. For example, if we’re considering the idea of supporting High Dynamic Range (HDR) video ads in our ad platform, the following facts can be considered supporting market data:
- 13 out of 20 potential customers we interviewed rated HDR-support as very important in their choice of video platform
- 68% of consumer devices support HDR video
- 3 out of 11 competitors have HDR support; 4 more have it on their roadmap
Which ideas should we fully launch based on supporting data and facts?
- Anecdotal data – Anecdotal data shows that at least someone outside the building thinks this is a good idea, but because of the small sample it can also be just random noise. It’s a very unreliable source of evidence, which we tend to rely on way too often (especially when it supports our opinions). We should use anecdotal evidence to OK just very low-effort, very low-risk ideas.
- Market data – Market data mostly tells us there’s a demand for a solution, but it teaches us very little about our specific idea. Ideally we’d like to continue to test the idea, but if we don’t have the capacity, these are examples of ideas where it might be ok to take the risk:
- Incremental features that add new functionality (rather than change or subtract), and are unlikely to annoy anyone, for example HDR support
- Redesigns of parts of the UI that users don’t visit often — e.g. the settings page
- Short-duration, in-product promos and calls-to-action
Note: launching without testing is actually testing with 100% of users. So after the launch we must track the results very closely and be ready to roll-back or iterate on the idea quickly. We definitely don’t want to bloat the product with features no one uses.
We learn in-depth how to implement product discovery in my Lean Product Management workshops. Secure your ticket now for the next public workshop or contact me to organize an in-house workshop for your team. For more info see itamargiladcom/workshops.
Tests and Experiments (3 < Confidence Level)
Testing means putting a version of the idea in front of users/customers and measuring the reactions.
There are several sub-types of tests with growing associated costs and levels of confidence:
- Early-stage tests use a “fake product” or a prototype before the product is built, for example landing pages, wizards of Oz, concierge services, and prototype usability studies.
- Mid-stage tests, for example internal team dogfood, early adopter programs, alpha, real product-based usability tests, use a rough and incomplete version of the idea with a small group of users.
- Late-stage tests (e.g. betas, labs, previews) use an almost-complete version of the idea with a larger group of users
- Split tests (e.g. a/b, multivariate) test complete versions of the idea with lots of users, and include a control element to reduce the odds of false results.
- Launch tests use partial roll-outs to test the finished idea on a large scale.
Which Ideas should we launch based on Tests and Experiments
You should strive to test almost all of your ideas. The level of testing to use depends on the cost of the idea, the cost of the test, and your tolerance for risk. Here are some rules of thumb (but apply judgment):
- Early-stage tests may be enough in cases where the only risks you see are about market demand, usability, or pricing sensitivity, and the idea is cheap to build. For example, if we’re redesigning a part of the UI, but keeping all the functionality, a prototype-based usability test may be enough. If we’re planning to re-run last year’s Black-Friday promotion, but we’re unsure how to price it, we can run a fake door test.
- Mid-stage tests help answer questions about value in use, usability, and adoption and usage patterns. These are more expensive tests, and they’re enough to greenlight most medium risk and/or medium cost ideas. For example: a new core feature, removing or replacing an existing feature, a major redesign, minor new product.
- Late-stage tests and launch tests are dress rehearsals before the launch. Use these expensive tests: 1) when the idea is going to affect all/most users in a big way and you want to ensure it’s bullet-proof, or 2) when some assumptions can only be validated with large amounts of data. Examples include a brand new product, a major revision to an existing product, new pricing scheme, a new API.
- Split tests — Companies like Netflix, Booking.com and AirBnB run every idea, no matter how small, through an A/B or multivariate experiment. This is good practice that drastically reduces the odds of launching bad ideas. If your capacity to run split tests is more limited, use them for cases where you need quantitative data to validate the assumptions, for example to answer questions like: Will people choose this option? Will we earn more money? Will retention not degrade? Examples include UI design changes, new pricing, and in-product promotions and campaigns
When to stop testing is a judgment call. At a minimum we’d like to ensure that our most critical assumptions, the ones that may make the idea useless, are validated. However, aiming for 100% risk-free launches is not possible nor necessary, especially if it’s easy to revert the idea with no major damage.
Start Small, Keep Iterating
In practice we collect evidence of various types and gradually build a better understanding of the idea. We start with cheaper modes of validation (assessment, data gathering, early-stage tests), and move to more expensive ones only if the idea still looks good. Every time we collect new evidence we should reevaluate the idea and decide what to do next. This helps create true build-measure-learn loops, and helps us filter-out bad ideas quickly (Here’s a full real-world example of this process running through multiple validation steps).
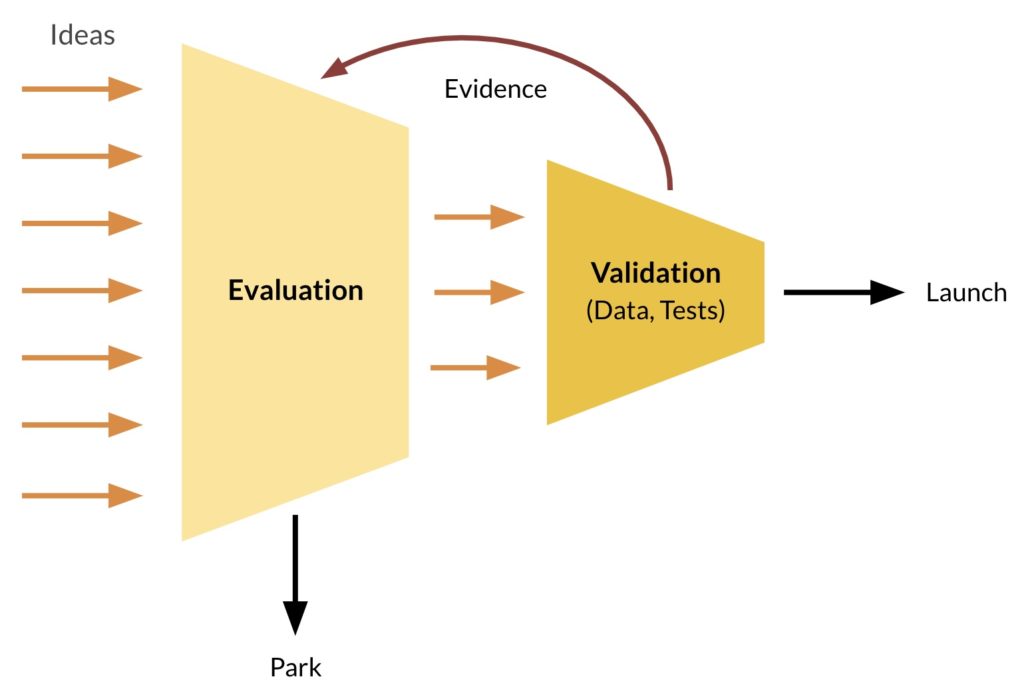
We stop iterating when we feel we have good-enough confidence to either launch the idea or to park it. The confidence meter can show you if you’ve reached the right level of evidence. For example, if the confidence level is below 0.1 you’re relying solely on opinions and should have near-zero confidence in the idea. If it’s below 1.0, you have only anecdotal evidence. However the confidence level alone can’t tell you when you’re good to go — when you’re striking the right balance of cost/risk/reward. I’ve listed some suggestions above, but there’s no simple formula — it’s always a judgment call. Nothing wrong with using your judgment, as long as it’s based on good practices and real evidence.
From readers:
“The grand unified theory of product management”, “Best Practical Product Management Guide”, “Must read for seasoned and new product managers”, “Top Five Business Book I’ve Ever Read”
